Nel campo della generazione di contenuti da parte dei modelli di intelligenza artificiale, un tema di fondo ha sempre accompagnato lo sviluppo tecnologico: riuscire a integrare pienamente, in un solo flusso di calcolo, le due grandi modalità espressive del linguaggio e delle immagini. Per anni, queste capacità sono rimaste separate, anche nei sistemi più evoluti. Era necessario, infatti, passare attraverso modelli distinti: uno dedicato alla comprensione e generazione del testo, un altro riservato alla creazione delle immagini, spesso richiamato attraverso un comando esterno. Questo approccio ha certamente portato risultati notevoli, ma presentava un limite evidente. Ogni elemento visivo veniva inserito a posteriori e non nasceva come parte organica della sequenza generata dal modello principale.
Con GPT-4o, questo limite viene superato. La differenza rispetto al passato è sostanziale: ora testo e immagine convivono davvero all’interno di un unico modello che li produce insieme, seguendo una logica unificata. Il merito va attribuito a una nuova architettura, denominata Transfusion, che riesce a combinare la forza predittiva dei modelli Transformer con la capacità progressiva di generare immagini tipica dei modelli di diffusione.
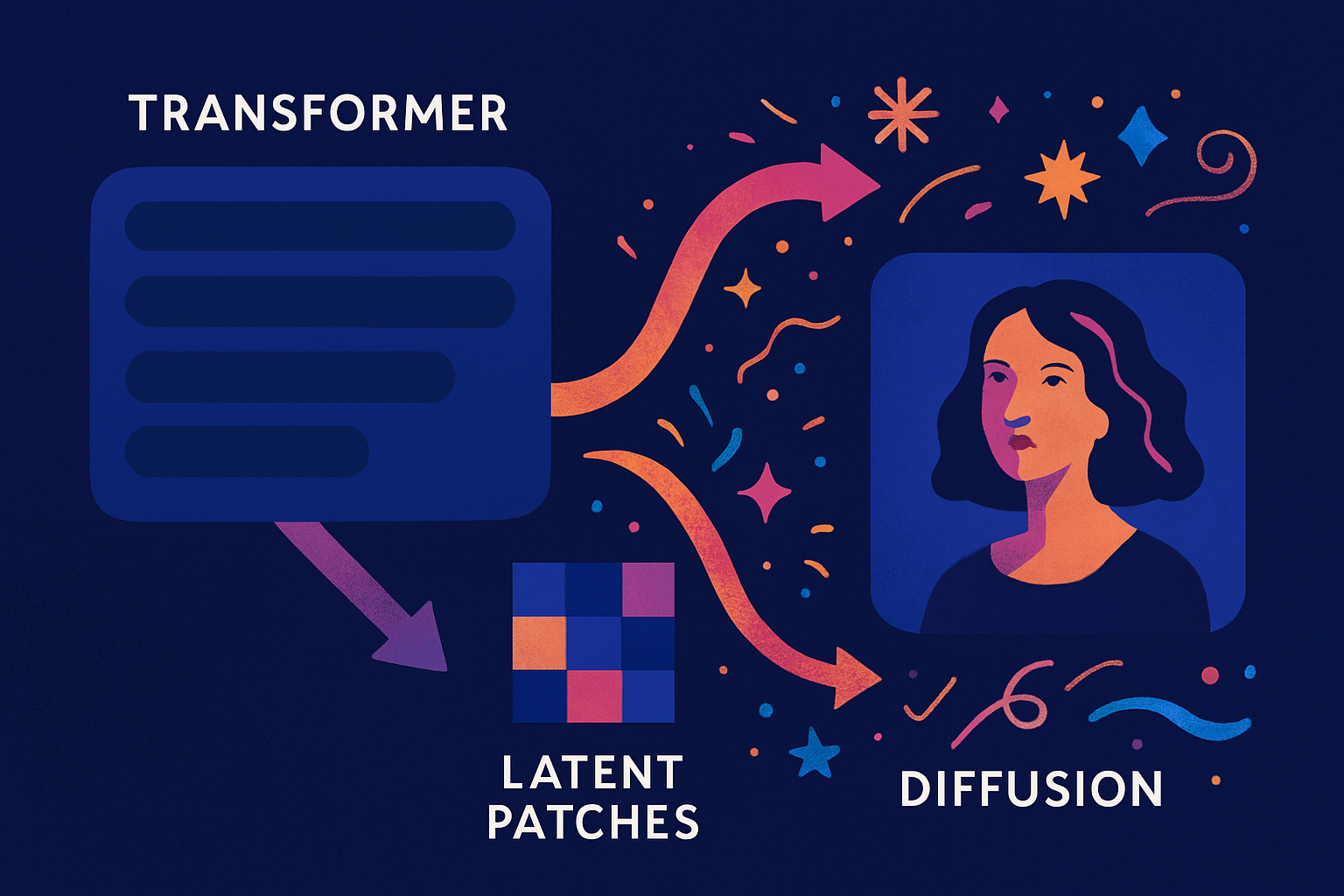
Il Transformer, che è ormai alla base della maggior parte dei modelli di linguaggio di ultima generazione, lavora sequenzialmente: prevede parola dopo parola, costruendo il testo passo dopo passo. La diffusione, invece, è una tecnica utilizzata per generare immagini partendo da rumore casuale, che viene poi raffinato progressivamente fino a ottenere un risultato nitido e dettagliato. L’innovazione di Transfusion sta nell’avere fuso questi due metodi in un’unica struttura coesa.
Quando il modello deve generare un’immagine, utilizza marcatori speciali che definiscono l’inizio e la fine della porzione visiva nella sequenza. Appena incontra il marcatore di inizio immagine, il modello inserisce una serie di vettori che, inizialmente, rappresentano puro rumore. Questi vettori sono le cosiddette “patch latenti”: frammenti numerici dell’immagine ancora indefinita. Attraverso più passaggi, questi dati vengono ripuliti e raffinati progressivamente, fino a diventare una rappresentazione dettagliata dell’immagine desiderata.
Le patch latenti derivano da una compressione iniziale operata tramite un autoencoder variazionale (VAE). Questo componente riduce la complessità dell’immagine originale, trasformandola in un insieme di vettori latenti che catturano le caratteristiche salienti pur mantenendo una dimensione gestibile. In seguito, questi vettori vengono elaborati da layer specifici: il modello utilizza proiezioni lineari per adattare le patch allo spazio del Transformer e, opzionalmente, impiega blocchi di tipo U-Net che permettono di catturare strutture spaziali più complesse. U-Net agisce ampliando e raffinando i dettagli locali delle patch, sfruttando il suo schema di downsampling e upsampling per migliorare la definizione senza aumentare eccessivamente il carico computazionale.
In termini più semplici: prima di essere generata completamente, l’immagine viene compressa e ridotta a una versione semplificata, come se fosse un disegno abbozzato. Questo compito lo svolge l’autoencoder, che conserva le informazioni essenziali ma le rende più leggere da elaborare. Dopo questa compressione, il modello prende questi pezzi semplificati dell’immagine e li adatta per farli passare attraverso il suo sistema di calcolo. Per migliorare ancora di più il risultato, può usare un’ulteriore struttura chiamata U-Net, che serve a rendere più nitidi i dettagli e ad arricchire l’immagine, un po’ come se ripassasse il disegno iniziale con tratti più definiti, senza però appesantire troppo il lavoro del modello.
La scelta di lavorare con rappresentazioni continue, anziché con sequenze di token discreti, consente al modello di mantenere una quantità molto più elevata di informazioni durante il processo. Nei sistemi precedenti, infatti, le immagini venivano scomposte in una sequenza di simboli appartenenti a un vocabolario fisso. Questo approccio imponeva una compressione inevitabile dei dati visivi, limitando la capacità del modello di catturare sfumature di colore e dettagli sottili. Con Transfusion, questo ostacolo viene superato: le patch latenti sono vettori continui, non vincolati da una codifica rigida e capaci di descrivere le immagini in modo più fedele.
In fase di addestramento, il modello impara contemporaneamente due compiti. Da una parte, continua a migliorare nella previsione delle sequenze di testo, seguendo la logica tradizionale dei modelli di linguaggio. Dall’altra, affina la capacità di ripulire il rumore nelle patch latenti, avvicinandole sempre di più alle immagini finali. Questo doppio obiettivo viene raggiunto attraverso una funzione di perdita combinata: la cross-entropy per il testo e la perdita L2 per la componente visiva, che misura la distanza tra i vettori di output e le versioni “pulite” delle patch d’immagine.
Una volta completata la fase di denoising, le patch vengono decodificate attraverso un meccanismo interno al modello, restituendo un’immagine finita e ad alta risoluzione. Questo avviene tramite un’inversione del percorso iniziale: i vettori latenti, elaborati e affinati, vengono prima trasformati in tile di immagine grazie alle proiezioni lineari o, se si utilizza la configurazione più avanzata, dai blocchi U-Net. Successivamente, il decoder del VAE ricostruisce l’immagine finale, partendo da questi tile latenti e restituendo il risultato nei consueti canali RGB.
Tutto questo avviene senza mai uscire dal flusso del Transformer, il che permette una perfetta coerenza tra il contenuto testuale e quello visivo. L’intero processo di costruzione è condiviso, garantendo una stretta integrazione tra le modalità espressive.
Questa integrazione si riflette nei risultati concreti. Le immagini prodotte dal modello risultano ricche di dettagli rispetto ai metodi basati su token discreti e più rapide da generare. Transfusion riesce infatti a rappresentare un’immagine completa utilizzando molte meno unità di elaborazione rispetto ai modelli precedenti. Ciò significa sequenze più corte, tempi di generazione più rapidi e un consumo computazionale sensibilmente ridotto.
Durante i test di riferimento, GPT-4o ha dimostrato una qualità visiva superiore rispetto ad altri modelli della stessa scala, superando soluzioni di diffusione pure come DALL·E 3 e SDXL 1.0. Il modello è in grado di gestire con precisione anche dettagli complessi, come testi integrati nelle immagini o scene che comprendono più oggetti distinti, mantenendo sempre una coerenza visiva elevata.
Un altro elemento rilevante riguarda la flessibilità operativa. GPT-4o non si limita a generare immagini da una descrizione: è in grado di operare anche al contrario, ricevendo un’immagine come input e proseguendo generando testo, oppure modificandola e arricchendola in base a nuove istruzioni. Questo dialogo continuo tra linguaggio e visione apre scenari applicativi che vanno ben oltre la semplice creazione di contenuti statici, permettendo interazioni multimodali dinamiche e articolate.
A differenza di architetture più tradizionali, che si affidano a componenti esterni o a pipeline complesse, Transfusion integra tutto il processo in un unico modello autoregressivo. Questo semplifica la progettazione e l’utilizzo e consente anche un livello di coerenza interna che altre soluzioni non possono raggiungere.
La capacità di gestire immagini e testo all’interno di un unico ciclo di elaborazione, con una qualità elevata e un’efficienza notevole, traccia una strada verso strumenti sempre più potenti e versatili. GPT-4o è una dimostrazione concreta di questa evoluzione, capace di suggerire che la vera multimodalità, finalmente, non è più un obiettivo teorico, ma una realtà operativa e matura.

